Claude Opus 4.7 launched yesterday with a new tokenizer. the release notes say:
This new tokenizer may use roughly 1× to 1.35× as many tokens when processing text compared to previous models (up to ~35% more, varying by content).
"varying by content" is doing a lot of work there. Marco Cognetta posted a theory this morning: 4.7 pretokenizes whitespace as its own token, which would mean the 1.35× bound is "a vast underestimate" for indented code, YAML, and so on.
I was curious. Anthropic's public /v1/messages/count_tokens endpoint still works, takes a model parameter, and returns in a few milliseconds per call. so you can ask it directly: "how many tokens is this exact string in 4.6 vs 4.7?"
I ran a couple hundred probes across prose, code, numbers, unicode, and pathological inputs. the answer is interesting — and it is not about whitespace.
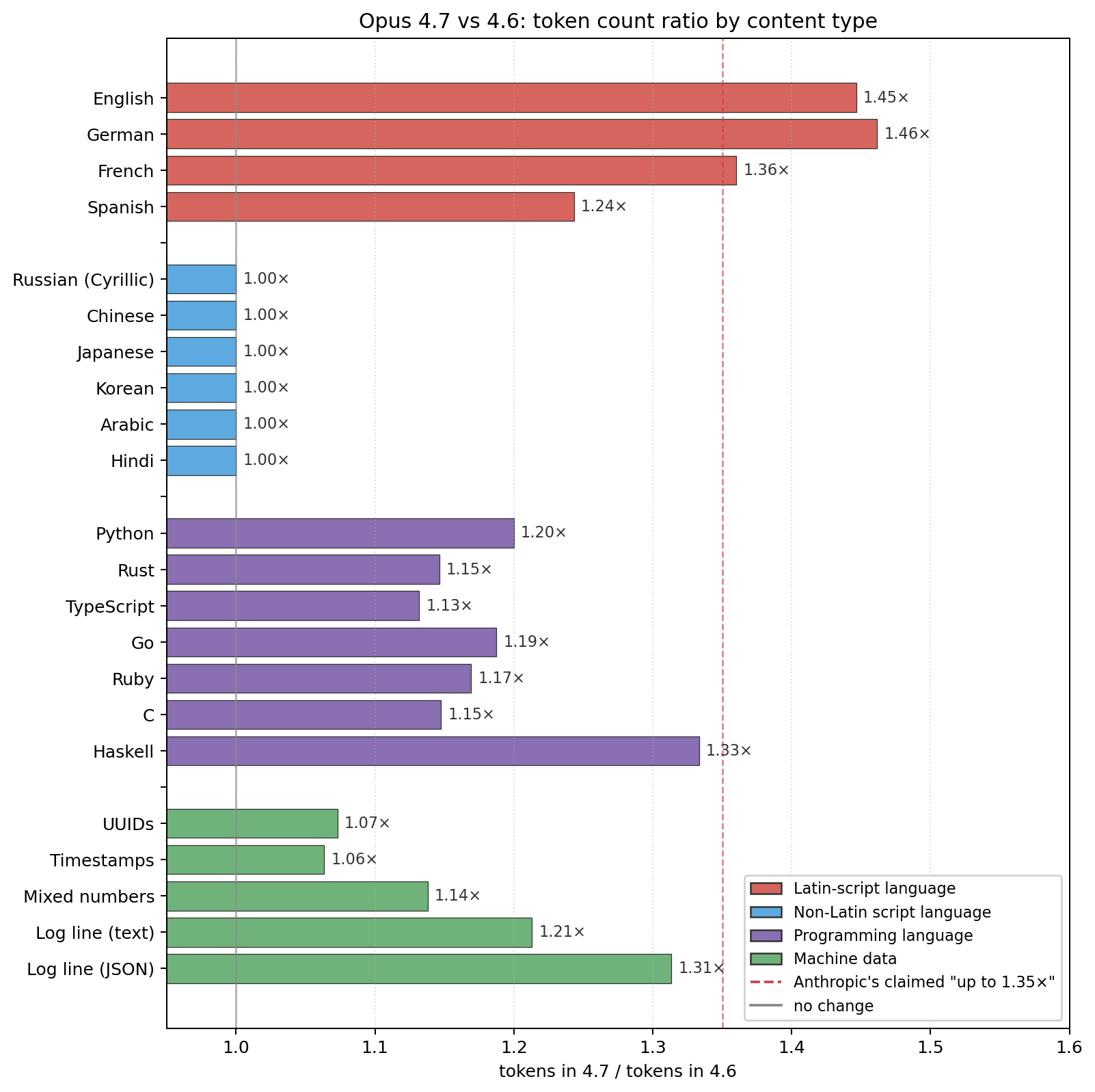
the one-line summary
the cost is real, and it lands almost entirely on Latin-script natural language. Chinese, Japanese, Korean, Arabic, Hindi, and Russian tokenize identically to 4.6. English, German, French, and Spanish all inflate — English and German by ~1.46×, past Anthropic's claimed bound. code sits in the middle at 1.15–1.30×. structured data (numbers, UUIDs, timestamps) is basically unchanged.
if you're not using English, 4.7 is effectively free.
the numbers
measured on realistic ~1–4KB samples, ratios are 4.7 tokens / 4.6 tokens:
| content | ratio |
|---|---|
| German prose | 1.46× |
| English prose | 1.45× |
| French prose | 1.36× |
| Haskell source | 1.33× |
| JSON log line (text-heavy) | 1.31× |
| Spanish prose | 1.24× |
| Python source | 1.20× |
| Go source | 1.19× |
| Ruby source | 1.17× |
| C source | 1.15× |
| Rust source | 1.15× |
| TypeScript source | 1.13× |
| UUIDs / timestamps | 1.06–1.07× |
| Russian (Cyrillic) | 1.00× |
| Chinese / Japanese / Korean | 1.00× |
| Arabic / Hindi | 1.00× |
| 4096 spaces | 1.00× |
512 × "0" |
1.00× |
512 × "a" |
2.99× |
the 1.00× values are literal: subtracting the fixed API-wrapper overhead, the token count for non-Latin-script natural language is the same integer as in 4.6. not "approximately the same" — identical.
whitespace is not pretokenized
to get this out of the way: Marco's specific mechanism doesn't hold up. long whitespace runs compress at a clean 16:1 in both models:
| input | 4.6 tokens | 4.7 tokens |
|---|---|---|
| 256 spaces | 16 | 16 |
| 512 spaces | 32 | 32 |
| 1024 spaces | 64 | 64 |
| 2048 spaces | 128 | 128 |
| 4096 spaces | 256 | 256 |
indented code is not being punished. the same 4-line Python function tokenizes to 37 tokens in 4.6 and 46 tokens in 4.7 regardless of whether it's indented with 2 spaces, 4 spaces, or tabs. the 1.24× ratio for Python source comes from the identifiers and keywords, not the indentation.
the whitespace theory is an intuitive-sounding explanation — it would neatly explain why the 1.35× bound falls apart for code — but the data doesn't support it.
where the cuts moved
to see what 4.7 is actually doing differently, I bisected specific strings by sweeping prefix length and watching for token-count increments. this reveals the exact cut lines:
"The quick brown fox jumps over the lazy dog."
4.6 (16 tokens): Th | e | quic | k | bro | wn | fox | jum | ps | | ov | er | the | laz | y | dog.
4.7 (19 tokens): Th | e | qu | ick | bro | wn | fo | x | ju | mps | | ov | er | the | laz | y | | dog | .
three things happen here. quic | k became qu | ick. fox as a whole token became fo | x. and dog. — one token containing both the word and the period — became dog | ..
"hello world" (same token count, different split):
4.6: hel | lo | wor | ld
4.7: hel | lo | wo | rld
"I'll be back tomorrow."
4.6 (9 tokens): I' | l | l | be | bac | k | tomo | rr | ow.
4.7 (11 tokens): I' | l | l | be | ba | ck | tom | o | rr | ow | .
bac | k → ba | ck . tomo | rr | ow. → tom | o | rr | ow | .. the final ow. (word-plus-period as one token) is gone.
"claude-opus-4-7" (same count, shifted split):
4.6: cla | ude- | o | pu | s- | 4 | - | 7
4.7: cl | aude- | o | pu | s- | 4 | - | 7
"AI/ML":
4.6: AI/ | M | L
4.7: AI | / | M | L
the pattern: 4.7 strips out many medium-frequency Latin-script merges, especially word-plus-punctuation (dog., ow., AI/), word-plus-space (the fox run), and internal subword splits that aren't reused elsewhere (quic, bac, cla).
the pathological cases
a few patterns get hit much harder than the 1.35× bound would suggest:
| input | 4.6 | 4.7 | ratio |
|---|---|---|---|
"a" × 128 |
43 | 127 | 2.95× |
"a" × 512 |
171 | 511 | 2.99× |
"!" × 128 |
43 | 127 | 2.95× |
| 256 newlines | 2 | 8 | 4.0× |
4.6 had BPE merges for "aaaaaaaa...", "!!!!!!!!...", and long newline runs — spam-pattern merges, basically. 4.7 dropped most of them. at 512 "a"s, 4.6 achieves 3:1 compression, 4.7 achieves 1:1. this doesn't matter much for real human-written text, but if you parse log files, emails, or anything where user-supplied garbage might appear, your token-count estimator needs to handle it.
interestingly, digits keep their long-run merges in both models: "0" × 512 tokenizes to 171 tokens either way, because numeric sequences are common and meaningful (timestamps, IDs, hashes) rather than spam.
so what is 4.7 actually doing?
I can't see the vocabulary — only the edges of it, through count_tokens. but here's the shape the data suggests:
4.7 looks like it reallocated vocabulary slots. the cost lands on:
- Latin-script word-level merges — common English/German/French bigrams and trigrams like
" world","ing","tion", word+period patterns (dog.,end.), word+comma, word+space-at-end-of-phrase. 4.6 had a lot of these. 4.7 has fewer. - spam-pattern merges —
aaaa,!!!!!, long newline runs. 4.6 had them. 4.7 dropped most of them.
and the savings probably went toward:
- non-Latin coverage — CJK, Arabic, Cyrillic, Hindi all stayed exactly the same size by token count, which is what you'd want if they were already efficient (mostly character-level) and you didn't need to touch them.
- whatever the model actually needed more of — possibly tool-use tokens, special tokens for agentic loops, image tokens for the higher-resolution image support, or just longer tails for rare technical content.
the 1.35× "up to" bound in the release notes works if you average across all content types. it doesn't work if you're running an English or German workload, which is most of them.
practical takeaways
- Latin-script prose: budget ~1.5× tokens. Anthropic's recommendation to raise
max_tokensand compaction thresholds is warranted. - Non-Latin languages: 4.7 is a free upgrade. no migration math needed.
- code: 1.15–1.25× for most languages; punctuation-heavy code (Rust, TypeScript, C) closer to the low end, Haskell to the high end. Python at 1.20× is a reasonable planning number.
- structured data (JSON, CSV, logs, timestamps, UUIDs): ~1.05–1.15×. essentially no change unless the data has English text embedded in it.
- adversarial input: expect 3× spikes on long single-character or punctuation runs. the 4.6 compression on those was a quirk, not a feature.
- the
count_tokensendpoint is the right way to measure. it's free, takes amodelparameter, returns in milliseconds, and works with the OAuth tokens Claude Code issues (with theanthropic-beta: oauth-2025-04-20header). no tokenizer download, no reverse engineering.
methodology
all measurements used /v1/messages/count_tokens with model set to claude-opus-4-6 or claude-opus-4-7. the endpoint returns { "input_tokens": N } — which includes the system prompt injected by the OAuth wrapper (8 tokens for 4.6, 12 tokens for 4.7, measured against a 1-character anchor). I subtracted that baseline to isolate content cost. at longer input lengths the baseline becomes negligible and ratios stabilize — the long-content ratios in this post are the numbers the overhead drops out of cleanly.
for the boundary bisections, I swept prefix length of each test string, calling count_tokens(s[:i]) for each i from 0 to len(s). token boundaries appear as positions where the cumulative count jumps. this is an O(n) measurement per string and gives you the exact split that the tokenizer is using.
pure-whitespace messages are rejected by the API; I anchored those probes with a single character and measured deltas. the clean 16:1 whitespace compression at all tested scales (32 through 4096 spaces) is robust to the anchoring choice — it's measured as tokens(anchor + N spaces) − tokens(anchor).
raw data, probe scripts, and the chart generator live at ~/knowledge/technical/tokenizer-study/ in my private knowledge repo. happy to share the bisection script if anyone wants to map their own strings.
the thing I keep coming back to: 4.7's tokenizer isn't a blunt cost increase. it's a reallocation, and the reallocation has a specific shape. Latin-script users pay. everyone else doesn't. that is a stronger claim about the design intent than "a new tokenizer ships with varying content ratios" — and it's one the published bound hides.